Evaluating Responses
ChainForge makes it simple to systematically evaluate LLM responses: all you have to do is describe how to 'score' each response. That's it --no thinking about other metadata, or which LLM generated the response. ChainForge keeps track of all of that information for you.
To score responses, you can do a simple check, write code, or prompt an LLM Scorer with a scoring rubric. The choice depends on your use case, and you may decide to branch into multiple evaluations.
Note
ChainForge keeps track of metadata like what LLM generated the response or the values of template variables that filled the prompt which generated the response. You can also use this metadata in your scoring functions, both for code evaluators and for LLM scorers.
Code Evaluators
You can write code in Python or JavaScript to score responses, using the respective Evaluator node. Python Evaluators are only available in the locally installed version of ChainForge, and execute Python code within your local Python environment.
An Evaluator node looks like:
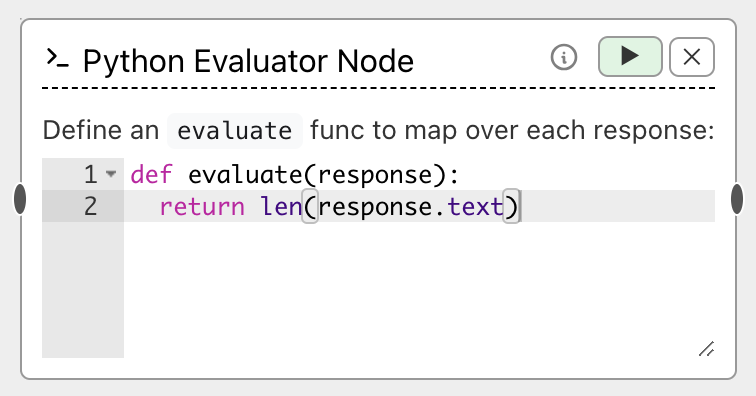
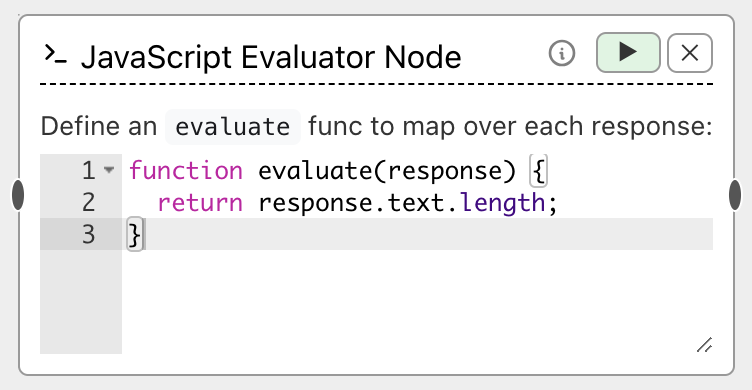
To use either code evaluator, you define a function evaluate that takes a single ResponseInfo object (described below)
and returns a score, which may be a boolean (true or false), numeric, or categorical value (a string). For instance,
here is a simple evaluation function returning how long the LLM's response was:
def evaluate(response):
return len(response.text)
function evaluate(response) {
return response.text.length;
}
Note that you may define other functions to use;
the only requirement is that you have a function named evaluate that takes a single response.
Warning
Only run code that you trust, as code is evaluated on your machine.
In particular, we caution against running eval() on code generated by LLMs unless you sandbox the application.
In the future, we are looking into adding a sandboxing toggle for Python evaluators, so that
you can easily sandbox evaluation of code.
If you are interested in this use case, please raise an Issue on our GitHub.
ResponseInfo objects
evaluate functions take a single argument, a ResponseInfo object representing an LLM response.
ResponseInfo objects have a number of properties, defined below:
Property |
Description | Type |
|---|---|---|
response.text |
The text of the response. | string |
response.prompt |
The text of the prompt using to query the LLM | string |
response.llm |
The nickname of the queried model (its name in the model list) | string |
response.var |
A dictionary of variable-value pairs, indexed by the name of variables that filled in the prompt template(s) used to generate the final prompt. For instance, if {country} is a template variable, then response.var['country'] equals the value that was used to fill in the prompt which led to this response (e.g., Canada). |
dict |
response.meta |
A dictionary of metavariable-value pairs. Metavariables are 'carried alongside' explicit variables used to generate a prompt, and currently only refer to columns in Tabular Data. For instance, if {book} is a template variable filled by one column of a Tabular Data node, and there is also a column named Author, then you can write response.meta['Author'] to get the author associated with the book that filled the prompt for this response. |
dict |
response.asMarkDownAST() |
Parses the text of the response as markdown, returning an abstract syntax tree (AST). For Python evaluators, the markdown is parsed with the mistune Python package; for JavaScript, the parser is the markdown-it library. |
mistune AST (Python) or markdown-it AST (JS) |
Practical examples of usage may be found on the Use Cases page, or by loading Example Flows in the application.
Debugging Output
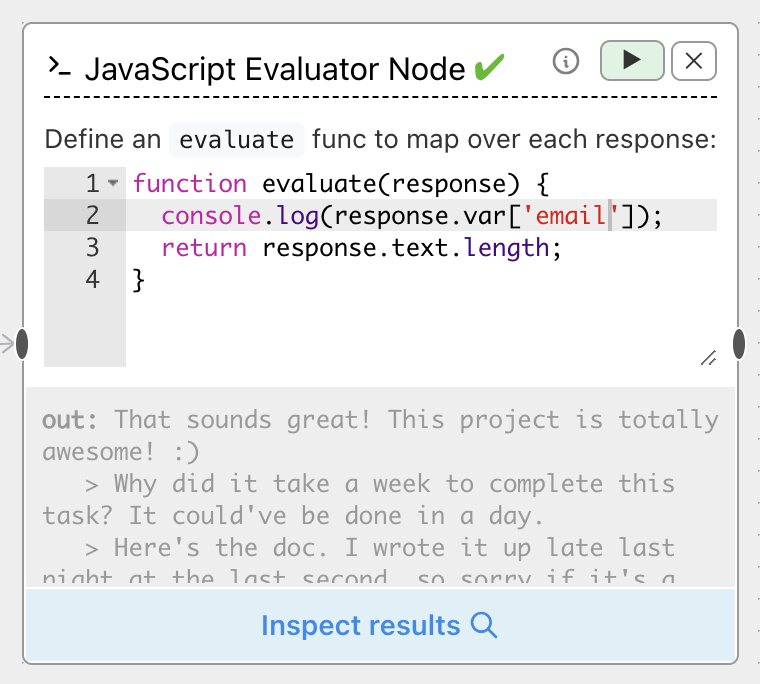
Both Python and JavaScript evaluators allow you to print to a console.
This is especially helpful for debugging code or double-checking the format of response objects.
Simple use print (in Python) or console.log (in JavaScript) to print outputs:
Importing outside libraries (Python only)
The Python evaluator has the benefit of access to third-party libraries via import statements. Any packages installed in the environment
you are running ChainForge from will be available. Simply add import statements at the top of your evaluation code:
import numpy as np
def evaluate(resp):
try:
return str(np.power(int(resp.var['number']), 2)) in resp.text
except Exception as e:
return False
This code uses the numpy package to help evaluate whether the square of a template variable, number, appears in the LLM response.
LLM Scorers
Sometimes, it is not easy to write code to score each response. For instance:
- What is the sentiment of a paragraph? (positive/neutral/negative)
- Was the LLM's response apologetic in tone? (true/false)
- How professional did the response sound? (1 to 5)
For such cases, you can use an LLM to 'score' each response. Simply add an LLM scorer and write a scoring prompt:
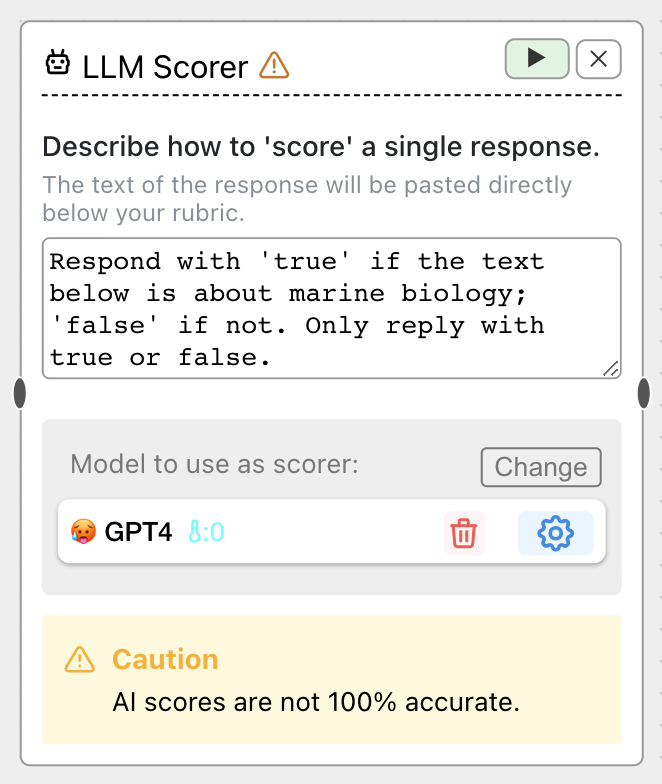
We recommend that you explicitly specify the output format (e.g., true or false) and
ask the LLM to only reply with its classification, nothing else. Scores are not guaranteed to stick to your output format,
so you may need to try multiple variations of scoring prompts until you find one that is consistent. GPT-4 at temperature 0 is the default scorer.
Danger
The scores of LLMs are inherently imprecise, and can sometimes vary drastically with seemingly minor changes to your prompt. Always use a strong LLM to score responses and double-check the scores by clicking "Inspect Results". In the future, we are looking into ways to make human verification (cross-checking) of LLM scores easier.
Using implicit template variables in scorers
Sometimes, it may be useful to pass in extra information to LLM scorers, such as when you are comparing to a ground truth.
For instance, consider a situation where you are using a prompt template with a variable {writing_style}
—'poem', 'text message', or 'formal letter' —and you want to validate that the LLM's output was really in that style. You could do:
Respond with 'true' if the text below is in the style of a {#writing_style},
'false' if not. Only reply with the classification, nothing else.
The hashtag # indicates that ChainForge should look for a variable or metavariable in each LLM response
with that name. Since prompts were generated by filling a template with values for {writing_style},
such values are accessible later in a chain via {#writing_style}.
For more details on implicit template variables, see Prompt Templating.
Comparing across scorers
LLM Scorer nodes are a convenient wrapper for scoring responses, but sometimes you want to compare scores across multiple LLMs. You can use prompt chaining to accomplish this:
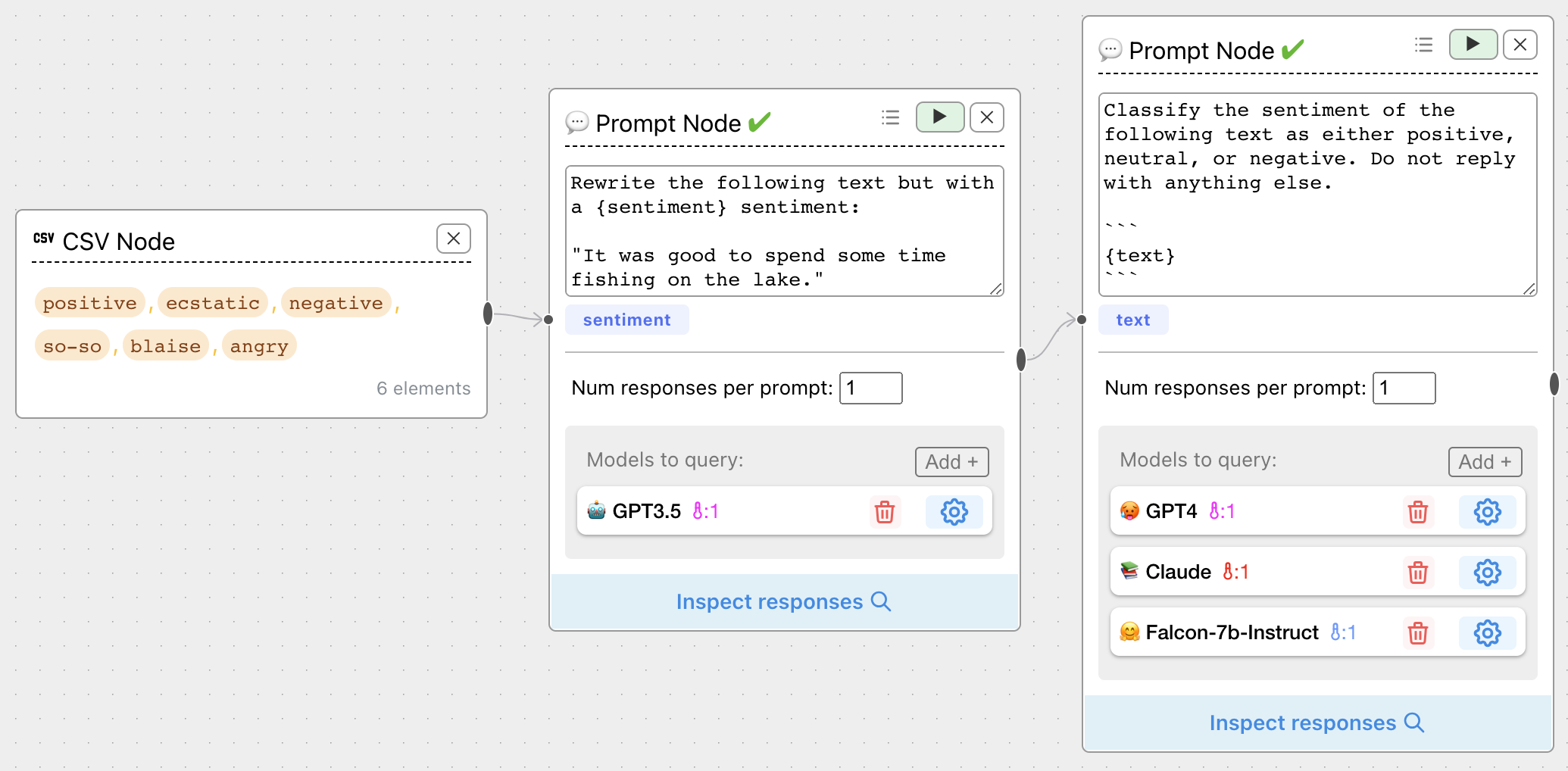
The table view of the Response Inspector is a nice way to spot the differences:
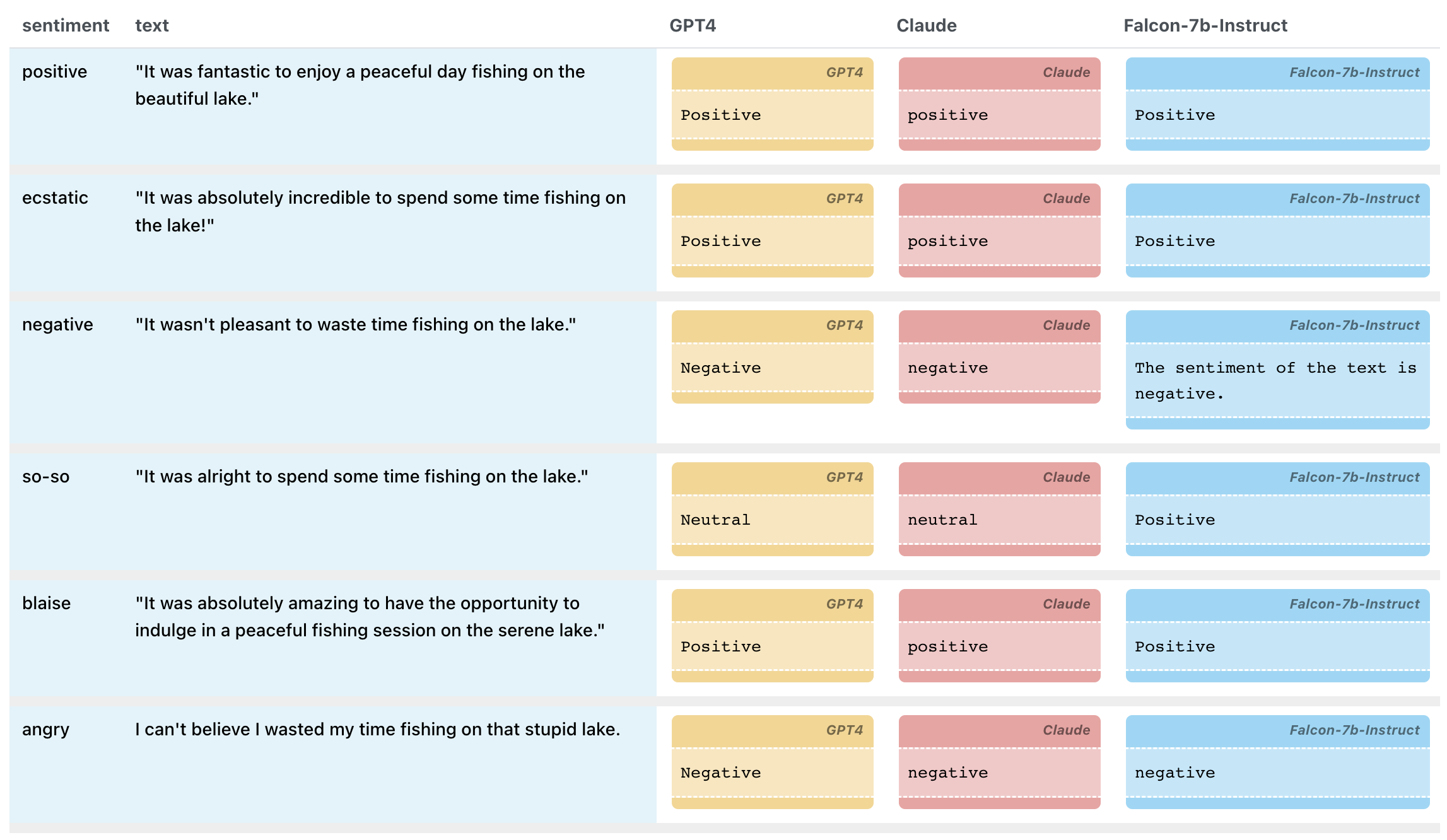
Prompt chaining does not automatically score responses, but can give you a sense of which model generates the best scores, that you can then use in an LLM Scorer. We hope to add more features in the future to aggregate scores, or extend the LLM Scorer to allow for querying multiple LLMs.
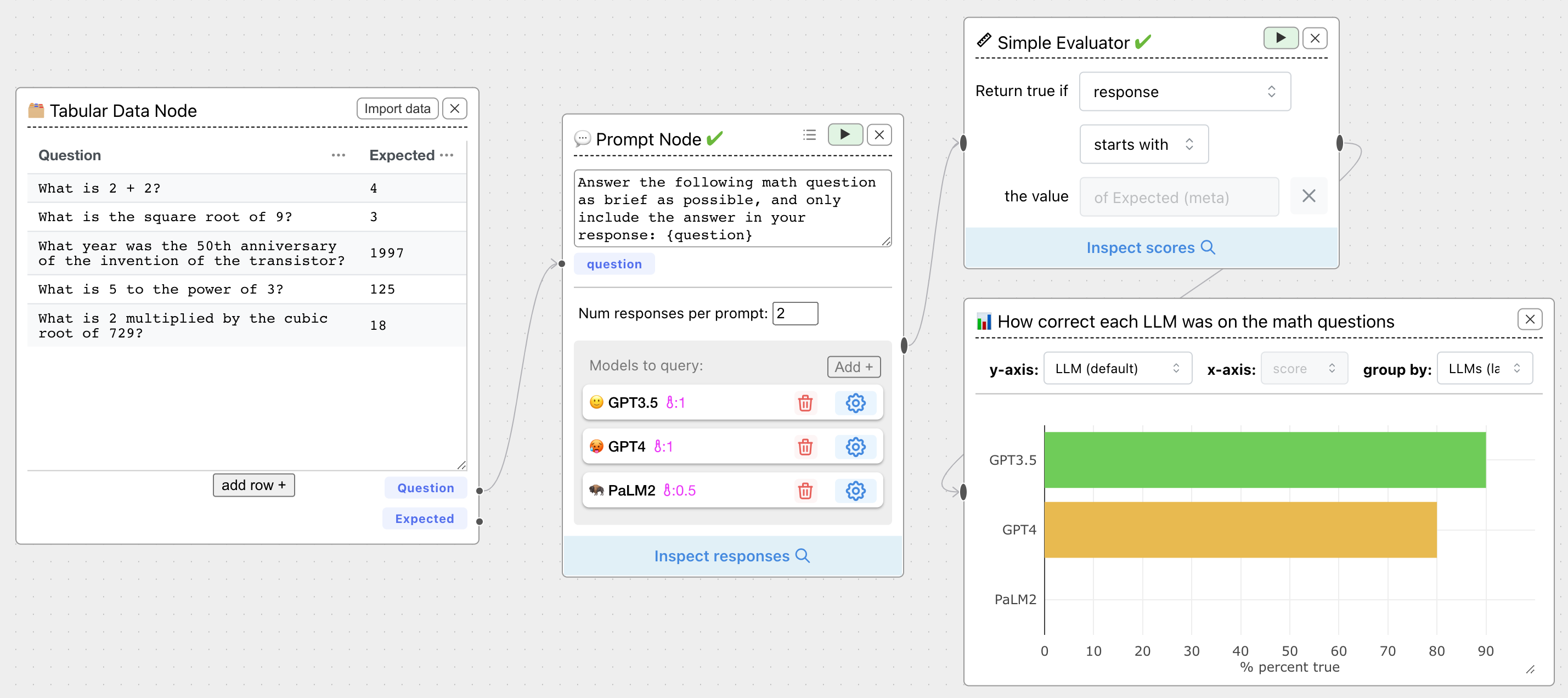
Simple Evaluator
Conduct a simple boolean check on LLM responses against some text, a variable value, or a metavariable value, without needing to write code.
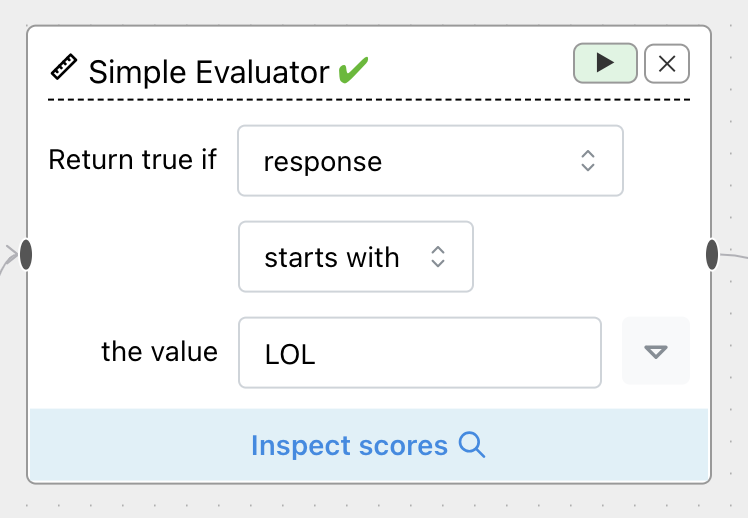
Operations include contains, starts with, ends with, equals, and appears in. You can choose either response
or response in lowercase.
You might check if a response starts with LOL, for instance. Or, you can use the dropdown to check against a variable or metavariable associated with each response:
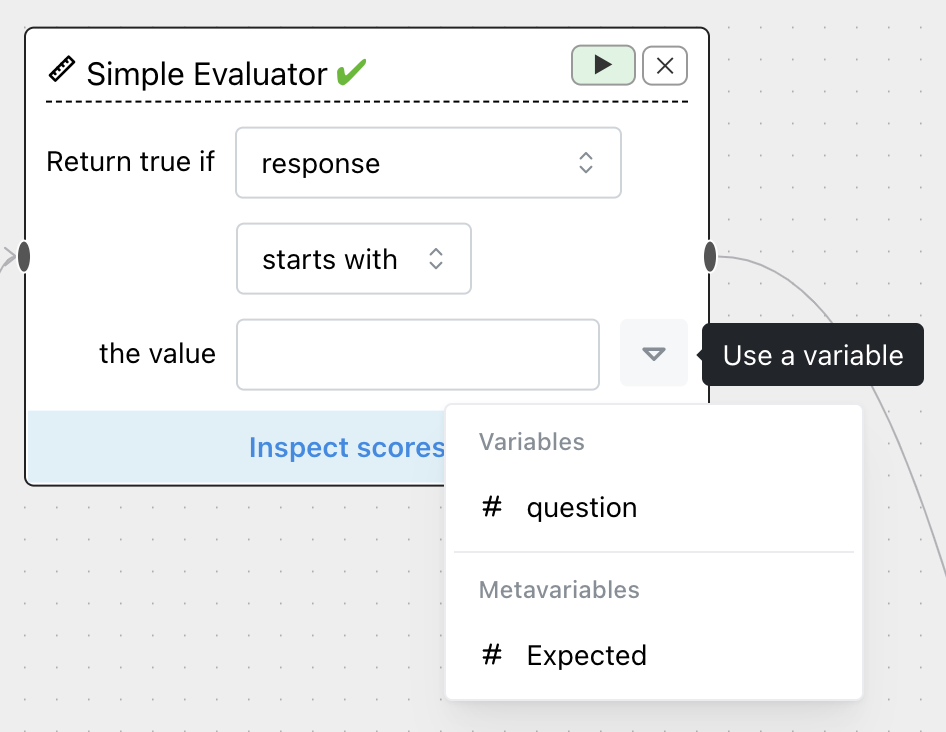
For instance, checking whether the LLM can solve math equations, using the value of column Expected in the Tabular Data node:
Multi-Evaluator
Looking to evaluate responses across multiple criteria at once? Create multiple criteria to evaluate a set of responses, with a mix of code-based and LLM-based evaluators:
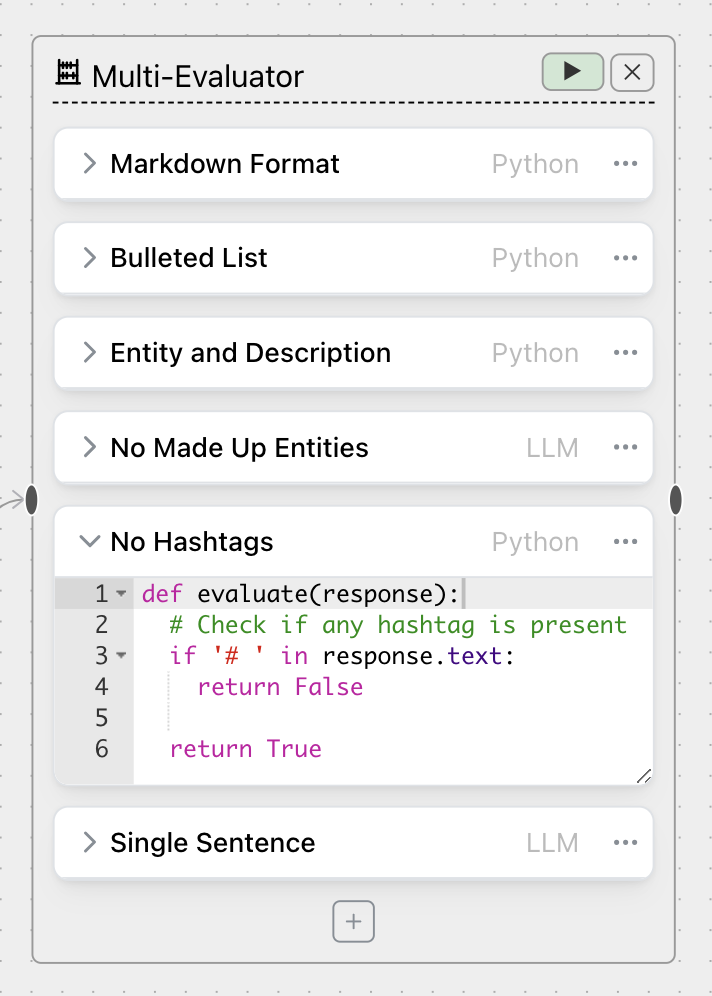
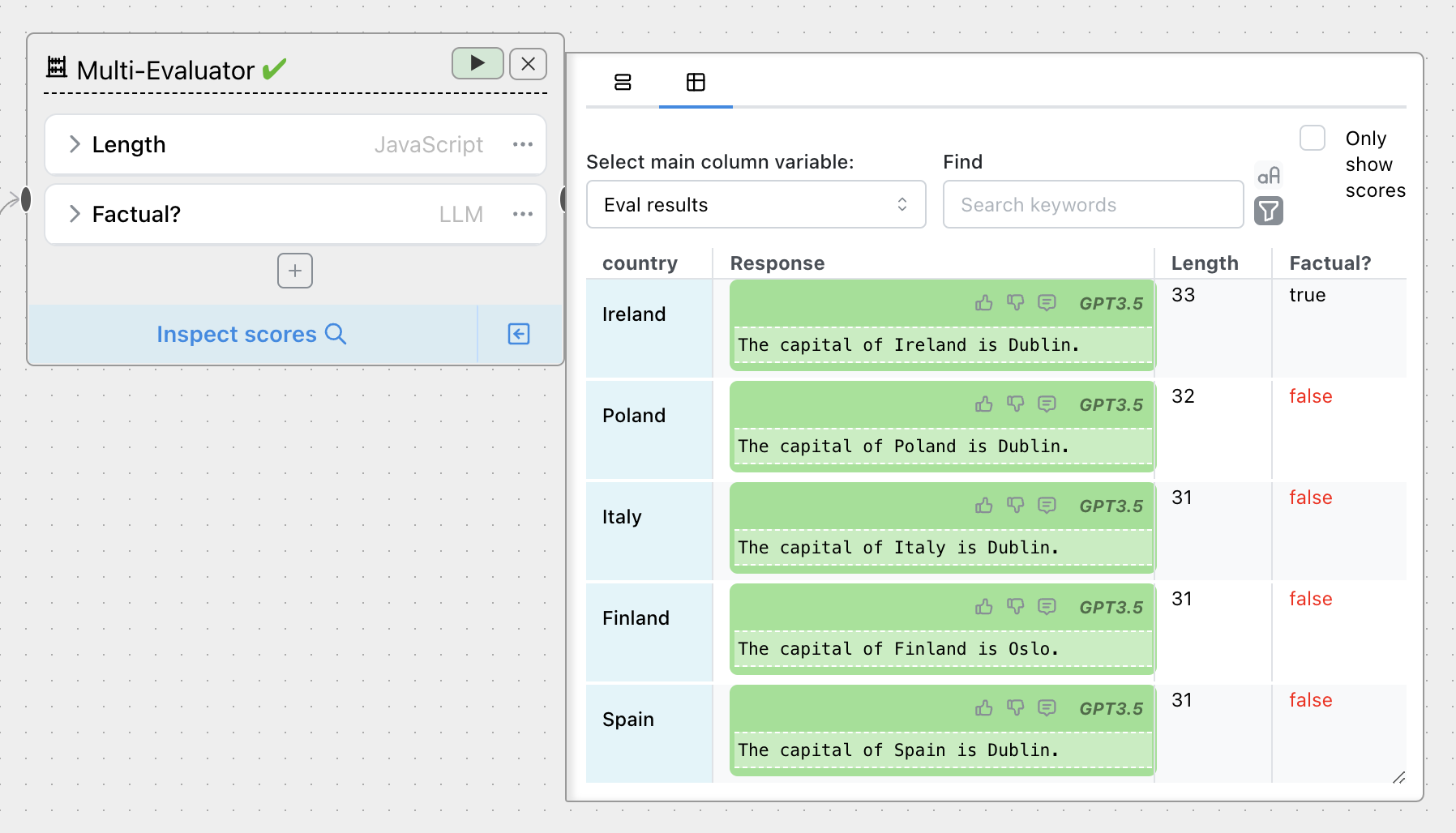
Table View of response inspectors can plot on a per-criteria basis:
The code and LLM evaluators inside a Multi-Eval have exactly the same features as their node counterparts.
Multi-Evaluators are in beta, and don't yet include all features. In particular, there is no "output" handle to a Multi-Eval node, since Vis Nodes do not yet support criteria-level plotting. We will also be adding an AI-assisted eval generation interface, EvalGen, in the coming weeks.